Security Footage - TryHackMe - Walkthrough
Extract images of a Wireshark capture.

Description
This is a walkthrough for the Security Footage challenge on TryHackMe, the room can be visited there, https://tryhackme.com/room/securityfootage.
Someone broke into our office last night, but they destroyed the hard drives with the security footage. Can you recover the footage?
Note: If you are using the AttackBox, you can find the task files inside the
/root/Rooms/securityfootage/directory.
The challenge provides us with a network traffic capture file.
Inspect the traffic
The file only contains one conversation. The HTTP/TCP conversation is between 192.168.1.100 and 10.0.2.15. If you inspect the conversation you will see that numerous images (identified by the Content-Type and the magic bytes) are send to through the conversation. This ans the challenge name is a strong indicator that this conversation is a stream of images from a security cam.
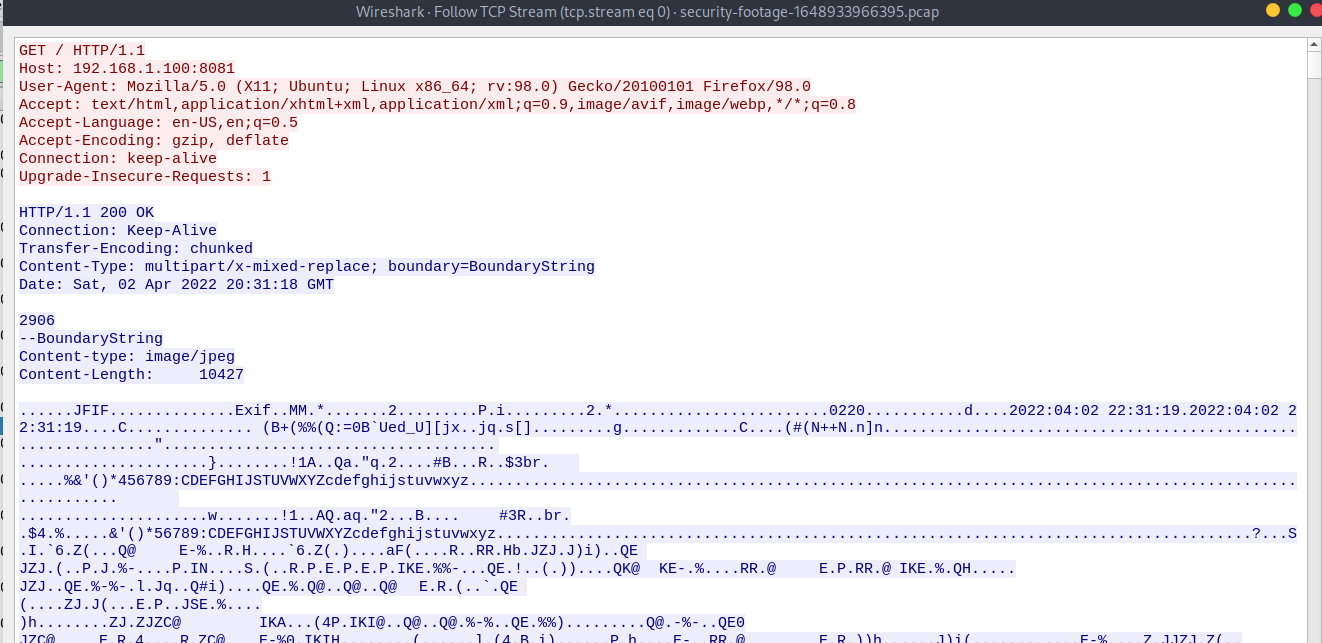
So to get the flag you should apparently extract the images, to do that I first extracted the conversation to a usable file.
1
tshark -r security-footage-1648933966395.pcap -qz follow,tcp,raw,0 | xxd -r -p > stream0_http.bi
Next I created a small script with the help of ChatGPT to extract the images.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import re
import os
INPUT_FILE = 'stream0_http.bin'
OUTPUT_DIR = 'images'
BOUNDARY = '--BoundaryString'
os.makedirs(OUTPUT_DIR, exist_ok=True)
def extract_images(filename):
with open(filename, 'rb') as f:
content = f.read()
parts = content.split(BOUNDARY.encode())
image_count = 0
for part in parts:
if b'Content-type: image/jpeg' in part:
match = re.search(b'Content-Length:\s*(\d+)', part)
if not match:
continue
length = int(match.group(1))
header_end = part.find(b'\r\n\r\n')
if header_end == -1:
header_end = part.find(b'\n\n')
if header_end == -1:
continue
image_data = part[header_end+4:header_end+4+length]
if len(image_data) == length:
output_file = os.path.join(OUTPUT_DIR, f'image_{image_count:03}.jpg')
with open(output_file, 'wb') as img_file:
img_file.write(image_data)
print(f"Extracted: {output_file}")
image_count += 1
if __name__ == '__main__':
extract_images(INPUT_FILE)
Create the directory for the images and run the script:
1
2
mkdir images
python3 extract.py
If you know inspect one of the images in the folder you will see some part of the flag on a display.

There will be over 500 such images, so it would be easier to merge the images to a video to read the flag. To do this you can zse ffmpeg, which is a handy tool when working with images and videos.
1
cat images/* | ffmpeg -framerate 30 -f image2pipe -i - -c:v libx264 -r 30 -pix_fmt yuv420p output.mp4